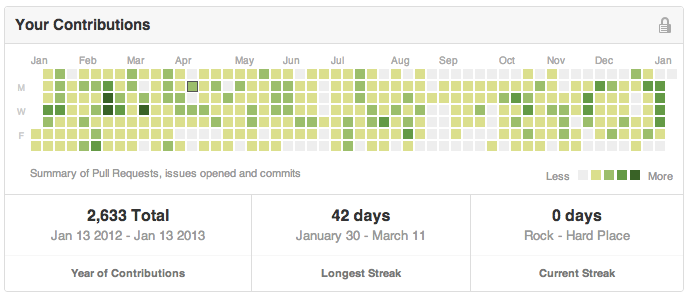
Rails 4 Engines
At TaskRabbit, we have gone through a few iterations on how we make our app(s). In the beginning, there was the monolithic Rails app in the standard way with 100+ models and their many corresponding controllers and views. Then we moved to several apps with their own logic and often using the big one via API. Our newest project is a single “app” made up of several Rails engines. We have found that this strikes a great balance between the (initial) straightforwardness of the single Rails app and the modularity of the more service-oriented architecture.
We’ve talked about this approach with a few people and they often ask very specific questions about the tactics used to make this happen, so let’s go through it here and via a sample application.
Rails Engines
Rails Engines is basically a whole Rails app that lives in the container of another one. Put another way, as the docs note: an app itself is basically just an engine at the root level. Over the years, we’ve seen sen engines as parts of gems such as devise or rails_admin. These example show the power of engines by providing a large set of relatively self-contained functionality “mounted” into an app.
At some point, there was a talk that suggested the approach of putting my our functionality into engines and that the Rails team seemed to be devoting more and more time to make them a first class citizen. Our friends at Pivotal Labs were talking about it a lot, too. Sometimes good and sometimes not so good.
Versus Many Apps
We’d seen an app balloon and get out of control before, leading us to try and find better ways of modularization. It was fun and somewhat liberating to say “Make a new app!” when there was a new problem domain to tackle. We also used it as a way to handle our growing organization. We could ask Team A to work on App A and know that they could run faster by understanding the scope was limited to that. As a side-note and in retrospect, we probably let organizational factors affect architecture way more than appropriate.
Lots of things were great about this scenario. The teams had freedom to explore new approaches and we learned a lot. App B could upgrade Rack (or whatever) because it depend on the crazy thing that App A depended on. App C had the terrible native code-dependent gem and we only had to put that on the App C servers. Memory usage was kept lower, allowing us to run more background workers and unicorn threads.
Read on →