
Architecture: Models
This is the first post in what I hope will be a series of articles about how we build things at TaskRabbit. Over time, we/I have internalized all kinds of lessons and patterns, but have never written them down explicitly and publicly. So let’s give that a try.
I thought we’d start with models. That’s what Rails calls database tables where each row is an instance of that model class.
Overall, we default to the following rules when designing the models in a system:
- Keep the scope small and based on decisions in the workflow
- Use state machines to declare and lock in the valid transitions
- Denormalize as needed to optimize use cases in the experience
Scope
When designing a feature (or the whole app in its early days), you have to decide what the models represent. I’m calling that the “scope” of the model.
For example, most applications have a User model. What columns will it have? Stuff about the user, obviously. But what stuff? One of the tradeoffs to consider is User vs. Account vs. Profile. If you put everything about the user in the same table as the one that’s pointed to in many foreign keys through the system, there will be a performance impact.
So we put the most commonly needed items on every screen load in the User model and “extra” stuff in the Profile.
User: authentication, name, avatar, stateProfile: address, average rating, bio information
There are plenty of ways to cut this up into other models and move things around, but that’s what I mean about “scope” of a model.
States
State machines are built into the foundation of the system. Almost every model has a state column and an initial state. There are then valid transitions to other states.
For example, there is a PaymentTransaction model. It has an initial “pending” state that represents the time between when an invoice is submitted and when we charge the credit card. During this time, it can move to a “canceled” state if it should not happen. Or, if things go as planned, it can transition to a “settled” state. After that, if there is an issue of some sort, it would go to a “refunded” state. Notably, going from “pending” to “refunded” is not a valid transition.
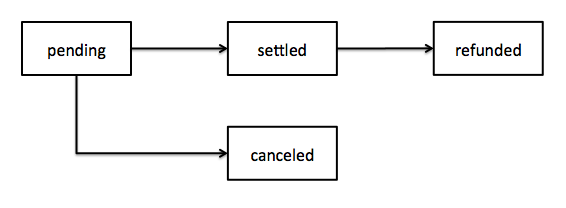
Creating these state and transitions preserves some sanity in the system. It’s a safety check. By asserting what is possible, we can (try to) prevent things that should not be possible.
Nouns and Verbs
The TaskRabbit marketplace creates a job that is sent to a Tasker. The Tasker can chat with the Client and can say they will do the job. Or they can decline. If they agree, they are officially assigned to the job and make an appointment. When they complete the job, they invoice the Client for the time worked. In most cases, it’s done at that point. In other cases, it is “ongoing” where they come back next week (to clean again, for example). At more or less any time, the whole thing can be canceled.
If given that description, you could come up with many possible model structures. They would all have a set of pros and cons, but many would work out just fine.
For example, you could have a Job model with these kinds of states: invited, invitation_declined, assigned, appointment_made, invoiced, invoice_paid, canceled, etc. Each would only allow the valid transitions as described above. You would also need the columns to represent the data: client_id, tasker_id, appointment_at, etc.
The main benefit of this approach is centrality. You can SELECT * FROM jobs WHERE client_id = 42 and get all of that user’s situation. Over time, however, we came to value a more decentralized approach.
Now, the models of our system reflect its objects and decisions that the actors make about them. Each fork in the experience has a corresponding model with a simple state machine.
For example, the Invitation model is created first to note the decision the Tasker must make. It then either transitions to accepted or declined. If accepted, it spawns an Assignment. It, in turn, can move to states like completed or ongoing.
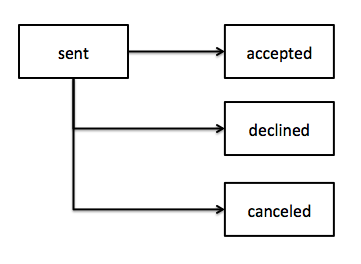
There is still the the Job model but it contains the “description” of the work to do and its id ties together the decision-based models.
Trade-offs
Everything is pros and cons. The decentralized approach has more global complexity (more objects and interactions) but less local complexity (simpler decisions, states).
It seemed to be the single, monolithic state machine that doomed the single Job model. Everything is fine as long as that’s the only path through the system. However, as soon as there is a new way for a Task to be assigned, we have a tangled web of states.
Not every task has the invitation pattern noted above. Some are “broadcast” to many Taskers at once and shown in a browse-able “Available Tasks” section in the their app. That’s a new fork in the experience. Ongoing tasks also create a state loop of sorts.
These cause the single state machine to get a bit tangled up, but is more easily handled in the decentralized approach. We can make a Broadcast model instead of an Invitation one. That can have its own set of states. Success in that local state machine can also spawn an Assignment and everything goes on as before.
Denormalization
To try and get the best of both worlds, we have also aggressively embraced a variety of forms of denormalization.
We actively try not to do SQL JOINs for simplicity and performance reasons, but that is at odds with all these little models all over the place. So we have said it’s OK to have duplicate data. For example, each of these “decision” models have the client_id, tasker_id, and pricing information. It just gets passed along. This makes everything a local decision and queries very straightforward.
The big hole in the decentralized approach is to “get all my stuff” easily. For that we have different tactics, both of which are denormalization with use cases in mind.
On write to an object, we can update a central model with the current situation for that Job. For example, when an Assignment gets created, we recalculate and store data in two different tables. One for both the Tasker and the Client on what they should be seeing on their respective dashboards. Thus, the API call to “get all my stuff” uses one of those tables. That is done in the same transaction as the original write.
The other option is basically the same thing but for either less time-sensitive data or more complicated queries. We use a message bus to observe changes. We then denormalize applicable data for a specific use case into a table or Elasticsearch. For example, when an Appointment is created, we would update the Taskers availability schedule in the database. Updating this schedule would also trigger an update to our recommendation algorithm which uses Elasticsearch.
One important note: all of these denormalizations should be idempotent. This allows us to recreate the whole thing from the source of truth or recover if any given event is dropped.
Summary
At TaskRabbit, we default to the following rules when designing the models in a system:
- Keep the scope small and based on decisions in the workflow
- Use state machines to declare and lock in the valid transitions
- Denormalize as needed to optimize use cases in the experience
As always, these are just the default guidelines. In any given case, there may be a reason to deviate, but it would have to be clear why that case was special.