
Resque Bus
At TaskRabbit, we are using Resque to do our background job processing. We’ve also gone one step further and used Redis and Resque to create an asynchronous message bus system that we call Resque Bus.
Redis / Resque
Redis is a single-threaded in-memory key/value store similar to memcached. Redis has other features like pub/sub and more advanced data structures, but the key feature that makes it an ideal storage engine for a queue and a message bus is that is can perform atomic operations. Atomic operations are the kind of operations you can expect to do on in-process data (like Array.pop or Array.splice) but in way that keeps the data sane for everyone connected to the database.
Resque is a background queue built on top of Redis. There seems to be other options out there these days, but we are pretty happy with Resque and associated tools/ecosystem. There is plenty of code in the resque codebase, but it all comes down to inserting json the queue, popping, and executing code with that as an input.
Resque Bus
Resque Bus uses Resque to create an asynchronous message bus system. As we have created more applications with interdependencies, we have found it helpful to create something like this to loosely couple the worlds. There are several other possible solutions to this problem, but I really felt that it was important to use something that our team understood well for this piece of infrastructure that we could easily modify and maintain.
Application A publishes an event
Something happens in your application and you want to let the world know. In this case, you publish an event.
1 2 3 4 5 | |
Application B subscribes to events
If the same or different application is interested when an event happens, it subscribes to it by name.
1 2 3 4 5 6 7 | |
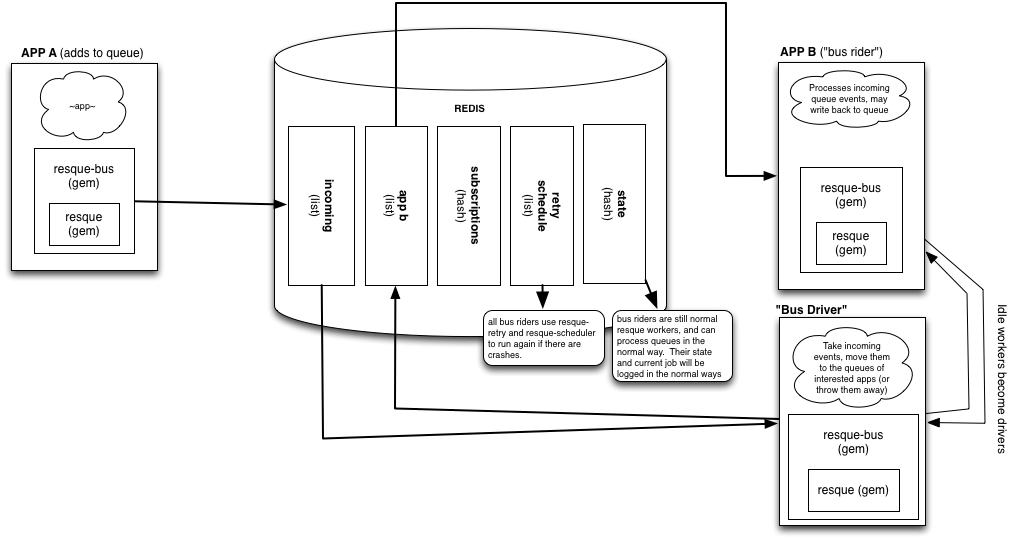
How it works
The following is how this workflow is accomplished:
- Application B subscribes to events (puts a hash in Redis saying what it is interested in)
- Application A publishes the event (puts published hash as args in a Resque queue called
resquebus_incomingwith a class ofDriver) - The
Drivercopies the event hash to 0 to N application queues based on subscriptions (arg hash now inapp_b_defaultqueue with a class ofRider) - The
Riderin Application B executes the block given in the subscription
Dedicated Setup
Each app needs to tell it’s subscriptions to Redis
$ rake resquebus:subscribe
The incoming queue needs to be processed on a dedicated or all the app servers.
$ rake resquebus:driver resque:work
The subscription block is run inside a Resque worker which needs to be started for each app.
$ rake resquebus:setup resque:work
If you want retry to work for subscribing app or you are using hte delayed publish_at syntax, you should run resque-scheduler
$ rake resque:scheduler
Combined Setup
This is the most dedicated way to run it, but all that resquebus:driver and resquebus:setup do is set the QUEUES environment variable. So you could run:
$ rake resque:work QUEUES=*
That would work only if you have a single app. While I believe this paradigm still adds value for a single app, it’s likely you have more than one app and the most important rule is to not allow Application C to process Application B’s queue, so that command would likely look more like this:
$ rake resque:work QUEUES=app_b_default,resquebus_incoming
It’s best practice to set your queue names, anyway. If you use resque-bus in the same Redis db as your “normal” Resque queues, then your full command set would probably look something like this:
$ rake resquebus:subscribe
$ rake resque:work QUEUES=high,app_b_default,medium,resquebus_incoming,low
$ rake resque:scheduler
It’s Just Resque
The above illustrates the primary reason that I like this system. It’s just Resque. While this may not be the most performant way to create a message bus, there are a number of good reasons to do so:
- Nothing new to monitor or deploy
- If used in a combined setup, you have nothing new to run
- If it stops processing a queue (downtime, during deploy process), it catches back up easily
- I understand what is going on (and resque has a simple data model in general)
- It’s portable. Resque has been re-implemented in a number of languages beyond ruby (we use a node.js rider for example)
- Many plugins already exist to add in extra capabilities (stats recording for example)
I feel that the “I understand point…” sounds a little like NIH, but it’s just really important to me to fully know where this critical data lives.
Of course, because it’s just Resque, there are known issues to work through:
- It’s relatively slow when compared with other systems. We’ve experimented with Node and Sidekiq to do the
Driverrole if this becomes an issue. - Redis does not have a good failover system so this adds a single point of failure to the system. We’ve been working on various techniques to mitigate this risk including replication and (failover tools)[https://github.com/twitter/twemproxy].
Use Cases
The effect on our apps from other apps publishing and subscribing ends up being one of focus. A request comes in to the web server and that code is in charge of accomplishing the primary mission, for example signing up a user. When this is finished, it publishes an event called user_created just in case other apps care.
Sometimes one or several apps do care. In the signup case, our marketing app subscribes and starts a campaign to onboard that user as effectively as it knows how starting with a welcome email. Our analytics app subscribes and lets various external systems like Mixpanel know. Our admin search tool subscribes to get that user in the index. And so on.
Most of our data goes through certain states. For example, a Task goes from assigned to completed. Overall, we have found that publishing when the states changes is just about always the right thing to do. Some of those events have many subscribers. Many events are completely ignored (at the moment) and that is fine too.
A few types of apps have evolved within this paradigm:
- Rails apps that subscribe and publish in order to achieve their goals
- Bus apps that are small and data driven that have no UI
- Logging and analytics apps that subscribe to record many events
Rails app communication
When a Task is posted on the site, the app publishes a task_opened event. This is a very important event and there are lots of subscribers. One of them is our Task-browsing app that helps TaskRabbits find the right job for them. It has its own codebase and storage designed to optimize this particular experience. When it receives the event about the new Task, it does all the calculations about who is right for the job and stores them in the way it wants to optimize the browsing. It is also subscribed to events that would indicate that the Task is now longer to be browsed by TaskRabbits. In these cases, it removes objects related to that Task from storage.
The separation described here between the two systems involved (Task posting and browsing) has had a few effects.
- Local simplicity has increased. Each system does what it does with simpler code than if it was all combined into the same thing.
- Local specialization has increased. For example, now that the browsing experience is separate in code, I feel better in choosing the right storage solution for that experience. When in one system, it feels like “yet another thing” added to something that’s already complicated.
- Global complexity has increased. This separation has a cost and it is in the number of moving pieces. More moving pieces adds maintenance costs through mysterious bugs, time in runtime execution, and overall cognitive load on the developer. It’s case by case, but we believe it can be worth it.
Finally, note that this Rails app also publishes events about the new TaskRabbits that are relevant to the Task.
Bus Apps
Specifically, the browsing application publishes N events, each about a notification that should occur because of the new Task. We have a class of application which has no UI and just listens on the bus. We call the app listening for notification events Switchboard. Switchboard is an example of what I called a “bus app.” A bus app exists to subscribe to various events and take action based on the data. In this case, Switchboard receives an event that indicates that a text message needs to be sent, so it does so. Or it can look at the user’s preference and decide not send it.
With this approach, Switchboard is able to accomplish a few things effectively:
- It is the only app that knows our Twilio credentials or how to format the HTTP call
- It is the only one that knows that we even use Twilio or what phone number(s) to send from
- It is the only app that decides what phone number to send to and/or how to look up a user’s preferences
- It can have a drastically reduced memory profile than a normal Rails app in order to be able to process more effectively.
- It provides a centralized choke point for all outgoing communications, making something like a staging whitelist easy to implement
In effect, ResqueBus and Switchboard create an asynchronous API. Simply knowing the terms of the API (what to publish) provides several benefits to the consuming apps:
- They don’t have to know how to send text messages
- They don’t have to know how to look up a user’s preferences or even phone number
- They don’t have to change anything if we decide to send text messages differently
- They can focus on the content of the message only
- They will not be help up or crash if Twilio is having a problem of some sort
Loggers
As noted, all of these benefits of decentralization come at the cost of global complexity. It’s important to choose such architectural areas carefully and clearly this approach is one that we’ve fully embraced. The addition of these “additional” moving pieces requires creation of new tools to mitigate the operational and cognitive overhead that they add. A good example that I read about recently was the ability Twitter has to trace a tweet through the whole lifecycle.
At TaskRabbit, the equivalent is an app called Metrics that subscribes to every single event. Case by case, the Metrics subscription adds some data to assist in querying later and stores each event. We store events in log files, and optionally, elastic search. When combined with unique ids for each event that subscriptions can chain along if they republish, this provides the capability to trace any logical event through the system.
That was the original goal of the system, but it somewhat accidentally had several effects.
- Again, the ability to trace a logical event throughout decoupled systems
- Centralized logging capability a la SumoLogic for free (any app can publish random stuff to bus)
- With minor denormalization and well-crafted queries, realtime business dashboards and metrics a la Mixpanel or Google Analytics
Subscriptions
There are a few other ways to subscribe to receive events.
Any Attributes
The first version of Resque Bus only allowed subscribing via the event type as show above. While I found this covered the majority of use cases and was the easiest to understand, we found ourselves subscribing to events and then throwing it away if other attributes didn’t line up quite right. For example:
1 2 3 4 5 | |
While this is fine, something didn’t sit quite right. It adds unnecessary load to the system that could have been avoided at the Driver level. The biggest realization is that bus_event_type is no different than any other attribute in the hash and doesn’t deserver to be treated as such.
In the current version of Resque Bus, this code is now:
subscribe “any_id_i_want”, “bus_event_type” => “task_changed”, “state” => “opened” do |attributes| TaskIndex.write(attributes[“id”]) end
This ensures it never even makes it to this queue unless all of the attributes match. I felt it was important to keep the simple case simple (so it’s still possible), but in the implementation the first subscription is equivalent to this:
1 2 3 4 5 | |
Subscriber Mixin
It feels really powerful and magical to put code like this in a DSL in your initializer or other setup code. However, when we started creating apps that had many subscriptions, it got to be a little overwhelming. For this we created an Object mixin for subscription.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
This really cleaned up subscription-heavy apps.
Note: This subscribes when this class is loaded, so it needs to be in your load or otherwise referenced/required during app initialization to work properly.
More to come
If people seem to like this approach and gem, we have lots of approaches and tools built on top of it that I’d be excited to make available. Let us know on Github that you like it by watching, starring, or creating issues with questions, etc.